Фишки Flux.1
Добиваемся лучших картинок от новой генеративной модели

Поддержка Flux в WebUI Forge
WebUI Forge — интерфейс к Stable Diffusion, любимый многими за его высокую скорость и удобство использования. Первая версия Forge вышла в феврале 2024 года, после чего много месяцев не получала обновлений. Длительное отсутствие разработки привело к созданию форка ReForge, который подробно описан в статье «ReForge. Улучшаем картинки, генерируемые Stable Diffusion». Но вот оригинальный разработчик Forge вернулся — и анонсировал крупное обновление проекта. В списке изменений — переход на Gradio 4 (стало немного удобнее, но ряд расширений перестал работать), использование последней версии PyTorch (стало еще быстрее), появление двух сотен встроенных стилей по примеру Fooocus того же автора (подробнее — в моей статье о нем) и новый механизм распределения видеопамяти, позволяющий достичь максимально возможной скорости генерации на конкретном железе.
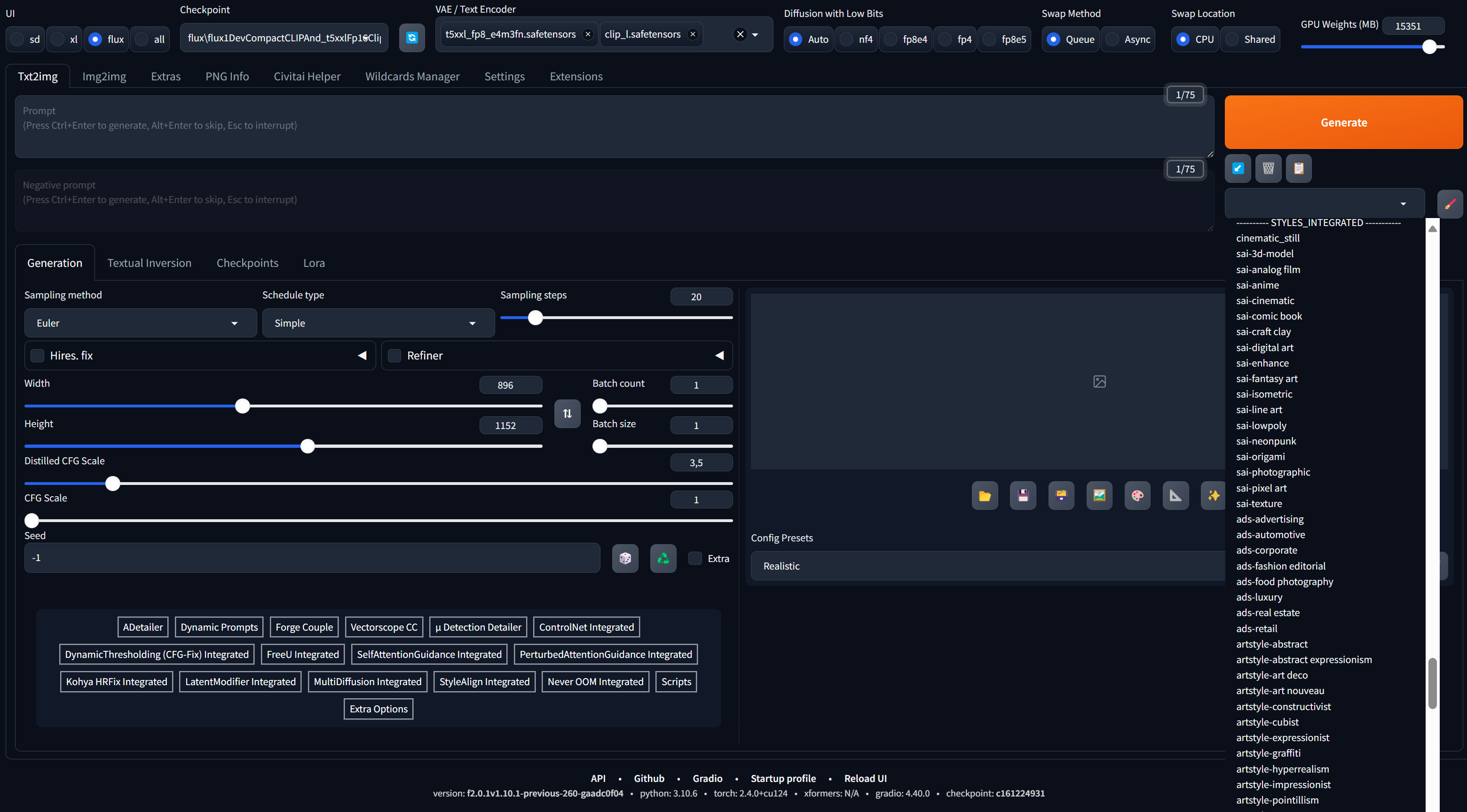
Нас же интересует добавление в WebUI Forge поддержки модели FLUX. Теперь можно использовать все возможные варианты модели от полноценной 16-битной до 4-битной NF4. Более того, можно отдельно выбирать VAE и модель (или сразу несколько моделей) текстового декодера.

Как это работает? Почти точно так же, как любая другая базовая модель, за исключением нового параметра Flux Distilled Guidance (в comfy/SwarmUI он называется Flux Guidance Scale), о котором будет чуть ниже. Достаточно переключить интерфейс в режим flux, выбрать модель из списка и указать требуемые VAE и текстовые декодеры.

NF4, FP16, FP8, Q8, GGUF: в чем разница?
Если ты будешь пользоваться Flux, то сильно облегчишь себе жизнь, если запомнишь, в чем разница между различными представлениями модели.
NF4 — это самый быстрый формат в плане скорости вывода результатов, но и самый непредсказуемый в плане разнообразия композиции по сравнению с другими форматами.
GGUF — сжатый формат, в котором может быть представлена модель. В отличие от формата safetensors, файл GGUF может содержать только одну сеть (диффузионную или текстовый декодер). В рамках формата GGUF все версии Q8, Q6 и так далее вплоть до Q1 — это варианты квантования моделей в порядке убывания качества и требований к железу. GGUF — самый медленный формат: при его использовании в режиме реального времени прямо во время генерации производится распаковка частей модели. Зато качество таких моделей максимально приближается к результатам форматов FP8 и FP16. GGUF совместим со всеми видеокартами, включая GTX, а младшие варианты можно запускать даже на видеокартах с минимумом памяти.
FP8 — вариант с несжатым 8-битным представлением. При этом аппаратное ускорение вычислений в формате FP8 поддерживается только на картах Nvidia, начиная с 40-й серии, из‑за чего модель в FP8 будет генерировать картинку дольше, чем полная модель FP16 (разумеется, при условии, что обе модели полностью уместились в видеопамять — что в случае с FP16 возможно лишь на топовых видеокартах). Если же объема видеопамяти недостаточно, чтобы в него полностью поместилась модель FP16, то FP8 создаст картинку быстрее.
Парадоксальным образом для видеокарт семейства RTX самым быстрым с вычислительной точки зрения форматом является FP16, а для старых моделей GTX — и вовсе FP32, который, разумеется, никоим образом не помещается в память этих моделей (размер модели Flux в представлении FP32 — около 46 Гбайт).
По скорости и точности работы модели соотносятся следующим образом:
| Критерий | Ранжирование |
|---|---|
| Точность | FP16 >> Q8 > Q4 |
| Точность для Q8 | Q8_K (модель отсутствует) > Q8_1 (модель отсутствует) > Q8_0 >> FP8 |
| Точность для Q4 | Q4K_S >> Q4_1 > Q4_0 |
| Точность для NF4 | NF4 между Q4_1 и Q4_0 (плюс/минус из‑за различия метрик) |
| Скорость (без выгрузки, для видеокарт от 24 Гбайт VRAM) | FP16 ≈ NF4 > FP8 >> Q8 > Q4_0 >> Q4_1 > Q4K_S > прочие |
| Скорость (с выгрузкой, для видеокарт с 8–16 Гбайт VRAM) | NF4 > Q4_0 > Q4_1 ≈ FP8 > Q4K_S > Q8_0 > Q8_1 > прочие ≈ FP16 |
Шпаргалка: какие файлы качать
Пожалуй, лучшим соотношением качества, скорости и совместимости обладают модели в представлении FP8 и формате safetensors. Модели Q8_0 в представлении GGUF поддерживаются пока не везде. Если остановить свой выбор на представлении fp8/safetensors, нам понадобятся:
- Диффузионная модель. Файл нужно положить в папку, в которой лежат все остальные базовые модели (например,
models/). В этой версии модели текстовые декодеры и VAE уже встроены, поэтому ничего дополнительного качать не требуется. Для использования модели достаточно будет выбрать ее из списка. Если же ты хочешь заполучить одну из моделей с альтернативным квантованием (например, Q8_0, качество которой практически неотличимо от полной версии FP16), то тебе придется скачать целых четыре файла, разложив их по трем разным папкам.Stable-Diffusion - Модель в формате GGUF (рекомендую вариант Q8_0) с сайта Huggingface. Нужно переместить в папку, в которой лежат все остальные базовые модели (например, models/Stable-Diffusion).
- Пара текстовых декодеров T5XXL (рекомендую версию FP8) и CLIP_L. Нужно положить в папку
models/.text_encoder - VAE: файл ae.safetensors с сайта разработчиков. Положить в папку
models/.VAE
После запуска WebUI Forge нужно переключить веб‑интерфейс в режим Flux и выбрать из списка модель. Если выбранная тобой модель — файл flux1-dev-fp8.safetensors, то после этого можно сразу запускать генерацию. Если же выбран файл в формате GGUF, то в дополнительном поле придется указать пару текстовых декодеров и VAE. В результате верхняя часть интерфейса обретет примерно такой вид, как на скриншоте ниже.
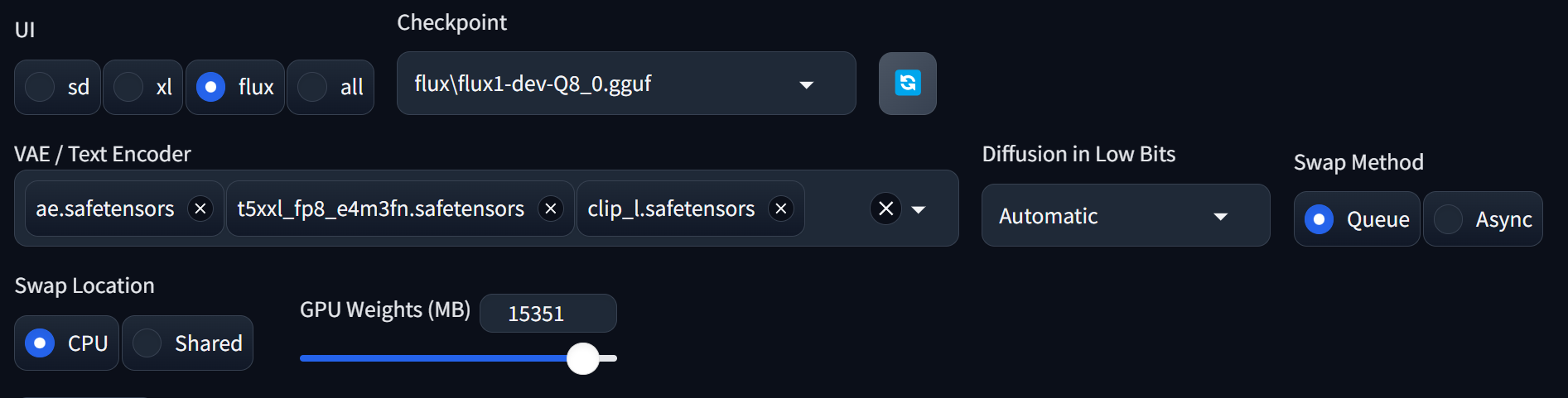
Теперь можно настроить разрешение картинки, установить число шагов, Distilled Guidance Scale (рекомендую начать со значения 2) — и можно генерировать картинки.
Даже если ты предпочтешь простой путь (интегрированный файл модели flux1-dev-fp8.safetensors), в будущем, вероятно, тебе все же придется научиться пользоваться отдельными текстовыми декодерами и VAE: из‑за существенно возросшего по сравнению с SDXL объема декодеров авторы новых моделей стали публиковать как интегрированные варианты, так и диффузионные модели отдельно. Подключать диффузионные модели и декодеры по отдельности не только удобно с точки зрения оптимизации использования видеопамяти, но и существенно экономит место на диске.
www
Как загрузить полную версию Flux в WebUI Forge (обсуждение на GitHub)
Запускаем Flux на старых видеокартах
В статье «FLUX.1 и SwarmUI. Генерируем картинки новой открытой моделью» подробно описан штатный сценарий использования модели, для которого нужно загрузить исходные 16-битные веса, отдельный VAE и файлы текстовых декодеров (которые, впрочем, загружаются автоматически). Полная модель тяжеловата для обычных видеокарт; ограничением выступает объем видеопамяти. Лучше всего себя чувствуют владельцы видеокарт с 16 и более гигабайтами видеопамяти; с некоторым трудом полная модель была втиснута и в рамки 12-гигабайтных моделей. Однако на руках у пользователей огромное число видеокарт с 6 и 8 Гбайт видеопамяти, и здесь оптимизации бессильны.
Первый вариант решения — конвертация модели в формат FP8. Чекпойнты dev или schnell в восьмибитном представлении на выбор можно скачать с сайта разработчика comfy: Dev, Schnell.
Восьмибитные версии модели подходят для видеокарт с 12 Гбайт видеопамяти и менее; скорость работы на картах с 8 Гбайт видеопамяти довольно низкая, но по крайней мере модель запускается. Качество по сравнению с 16-битными моделями страдает незначительно, так как 8-битная квантизация относится не к качеству финального изображения в формате PNG или JPEG, а к точности предсказаний (то есть 8-битная модель может демонстрировать огрехи при генерации мелких деталей, но характерных для 8-битных растровых картинок артефактов ты, разумеется, не увидишь).
Эти модели нужно поместить в основную папку, в которой лежат все базовые модели. В случае SwarmUI это папка Models/, WebUI Forge — models/. Отдельный VAE для этих версий скачивать не нужно.
Разработчик WebUI Forge пошел еще дальше, сделав модель пригодной для использования даже на очень старых видеокартах благодаря новой технологии квантизации NF4. По утверждениям разработчика, этот метод позволяет значительно повысить производительность на устройствах с ограниченным объемом видеопамяти (6, 8, 12 Гбайт VRAM), обеспечивая ускорение от 1,3 до 4 раз по сравнению с использованием формата FP8.
Сильная сторона NF4 — скорость: модели в этом формате работают значительно быстрее, чем FP8, особенно на видеокартах с меньшим объемом памяти и картах, не поддерживающих ускорение для формата FP8. Кроме того, размер модели в формате NF4 примерно вдвое меньше по сравнению с FP8.
По словам разработчика, NF4 превосходит FP8 в точности вычислений и обладает лучшим динамическим диапазоном: в отличие от FP8, к которой все коэффициенты представлены с восьмибитной дискретизацией, NF4 позволяет преобразовывать тензоры в комбинацию форматов float32, float16, uint8 и int4, что обеспечивает повышенную точность вычислений. Пользователи Reddit выложили достаточное количество сравнений, чтобы сделать вывод, что в реальности ситуация с NF4/FP8 далека от однозначной; в каких‑то случаях лучше показывает себя один вариант, в каких‑то — другой. Одно несомненно: 4-битная модель действительно работает намного быстрее, если запускать ее на карте с 6 или 8 Гбайт видеопамяти.
Модели NF4 поддерживаются как в новой версии WebUI Forge, так и в SwarmUI (коммит cdbe239).
На этом прогресс не остановился, и появились модели — как диффузионная, так и текстового декодера, представленные в сжатом виде с уменьшенной разрядностью.
Терминология: текстовые декодеры и квантизация моделей
Текстовый декодер — субмодель, которая часто (в случае SD 1.5 и SDXL — всегда) включается в файл основной модели. Используется для преобразования текстового запроса в токены (многомерные числовые векторы, указывающие направление в латентном пространстве), необходимые для генерации изображений. Модели ИИ не распознают вводимые запросы напрямую, они понимают только токены.
Модели и текстовые декодеры
- SD 1.5: только CLIP-L. В состав моделей входят также U-Net и VAE.
- SDXL: CLIP-L и CLIP-bigG. Эти декодеры входят в состав файла модели.
- SD 3: может работать с CLIP-L, CLIP-bigG и T5XXL, но T5XXL можно и не использовать, что снижает точность следования запросу.
- Flux: CLIP-L и T5XXL. Изначально модель была доступна в виде отдельных файлов диффузионной модели, текстового декодера и VAE, которые, в свою очередь, могут квантоваться разными способами (об этом ниже). В дальнейшем появились интегрированные модели, а еще чуть позже разработчики стали возвращаться к практике публикации отдельных субмоделей: размер декодеров Flux очень большой, вариантов квантования больше одного, форматов сжатия — тоже, и пользователям предлагается самостоятельно собрать себе полную модель из компонентов, которые поддерживаются на конкретном железе.
Квантование текстовых декодеров T5XXL
Изначально были доступны два варианта этого декодера: FP16 и FP8.
- T5XXL-fp16 точнее, но требует больше видеопамяти.
- T5XXL-fp8 менее точен, но менее требователен к оборудованию.
Со временем появились варианты, квантованные другими способами. Разницу между вариантами квантования декодера можно посмотреть в фотоальбоме или в обсуждении на Reddit.
Информация к размышлению: текстовый декодер T5 в версии XXL используется как в Stable Diffusion 3 (опционально), так и в моделях Flux. А разработан этот декодер компанией Google.
Квантование диффузионных моделей
Вариантов квантования диффузионных моделей Flux тоже множество. Самые точные 32-битные модели (FP32) полезны только для обучения; использовать их для генерации изображений — избыточно. Максимально доступная для локального использования модель Flux — 16-битная; результат работы сжатой модели с квантованием Q8_0 практически невозможно отличить от оригинала, а видеопамяти она требует меньше. Еще меньше видеопамяти потребляет модель FP8; дальнейшее уменьшение разрядности моделей все сильнее влияет на качество.
Модели GGUF: формат, отличный от привычного safetensors. В нем сохраняют квантованные диффузные модели; текстовые декодеры и VAE нужно подключать отдельно. Сейчас для Flux доступны все варианты от 16-битной до 2-битной Q2_K включительно.
Таким образом, в нашем распоряжении уже почти полтора десятка вариантов квантования диффузионной модели и столько же — декодера T5XXL.
В сухом остатке: если железо позволяет, используй оригинальную 16-битную модель Flux с сайта разработчиков. Для более слабого железа отлично подходит модель Q8_0; разницы с полной моделью ты, скорее всего, не заметишь. Для еще более слабого железа подойдет вариант FP8, у которого еще ниже требования к видеопамяти. Модели с более сильным сжатием заметно влияют на результат, не особенно снижая требования к железу (не забываем, что текстовый декодер все равно будет занимать заметную часть видеопамяти).
Пользователь Huggingface с ником city96 сконвертировал модель Flux в представление GGUF во всех возможных вариантах.
Скачать сжатую диффузионную модель можно с Huggingface; рекомендую версию Q8_0. Сравнение качества — на Reddit.
Кроме того, можно скачать и сжатую версию текстового декодера (при использовании WebUI Forge класть в папку models/text-encovers).
warning
На момент написания статьи WebUI Forge поддерживает диффузионные модели в представлении GGUF, но текстовые декодеры в GGUF не распознает. Вероятно, их поддержка появится в ближайшие дни; до тех пор можно использовать декодер T5 в представлении FP8. Поддержка GGUF появилась в CombyUI и SwarmUI совсем недавно; декодеры в этом формате нужно класть в папку SwarmUI/Models/clip, после чего декодер появится в виде доступной опции на вкладке Advanced Model Addons.
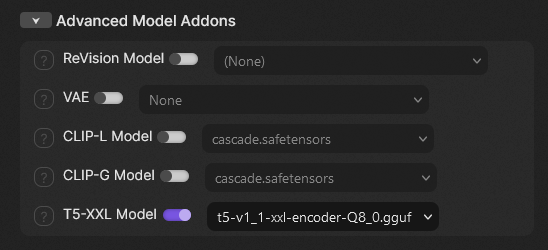
Что ж, с требованиями к видеопамяти и запуском модели в WebUI Forge разобрались; перейдем к решению других проблем модели Flux.
Решетка на плавных градиентах
В некоторых (далеко не во всех) генерируемых изображениях, особенно в максимальном разрешении модели, в области плавных переходов и градиентов Flux может создавать своеобразную «решетку», которая выглядит, как блочные артефакты компрессии наподобие JPEG. Однако это не они — хотя как знать; возможно, подобные артефакты присутствовали на изображениях, на которых обучали модель.
Более вероятна версия, что мы наблюдаем так называемые patch embed artifacts. Генеративные модели ИИ типа DiT в силу своей архитектуры могут демонстрировать искажения (артефакты), возникающие при обработке патчей изображения. Это означает, что даже при правильной настройке и обучении модели такие артефакты могут быть неизбежными и требуют специальных методов для их минимизации или исправления.

Патчи
В контексте генеративных моделей ИИ изображения делятся на небольшие участки (патчи), которые затем проходят через процесс встраивания (embedding). Артефакты могут быть визуальными или числовыми искажениями или особенностями, возникающими из‑за этого процесса. Например, артефакты могут проявляться как границы между патчами, что и приводит к наблюдаемому визуальному эффекту.
В рамках самой модели безболезненного способа исправить артефакты пока не найдено; включение опции Refiner Do Tiling в настройках второго прохода или апскейла хоть и помогает избавиться от этих артефактов, но, как и указано в описании‑подсказке к этой опции, привносит другие.
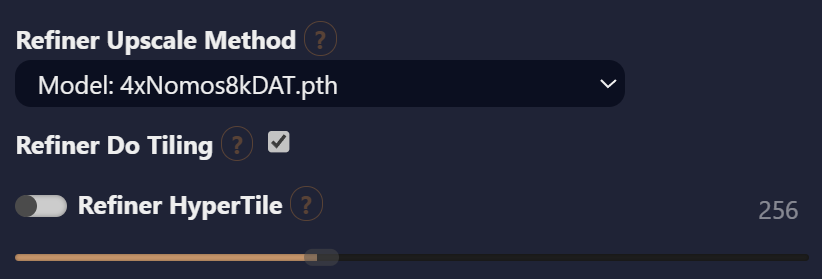
Проблему можно попытаться обойти, снизив выходное разрешение картинки до 1К, а потом воспользоваться апскейлом. Если же хочется применять модель в ее максимальном разрешении, то единственный найденный на сегодня способ — использовать для апскейла какую‑нибудь хорошую модель SDXL. Помимо избавления от блочных артефактов, использование такой модели для апскейла способно повысить качество и детализацию мелких текстур; сам процесс апскейла работает при этом быстрее, чем если повышать разрешение самой моделью Flux.
Недостатки у этого способа тоже есть. Немного (или сильно, в зависимости от значения параметра Refiner Control Percentage) меняются детали композиции (например, могут пострадать пальцы рук). Еще раз напомню, что при использовании для апскейла модели SDXL необходимо включить опцию Refiner CFG Scale, установив значение от 5 до 7 (стандарт для моделей SDXL). И не забудь включить основной переключатель справа от надписи Refine/Upscale.
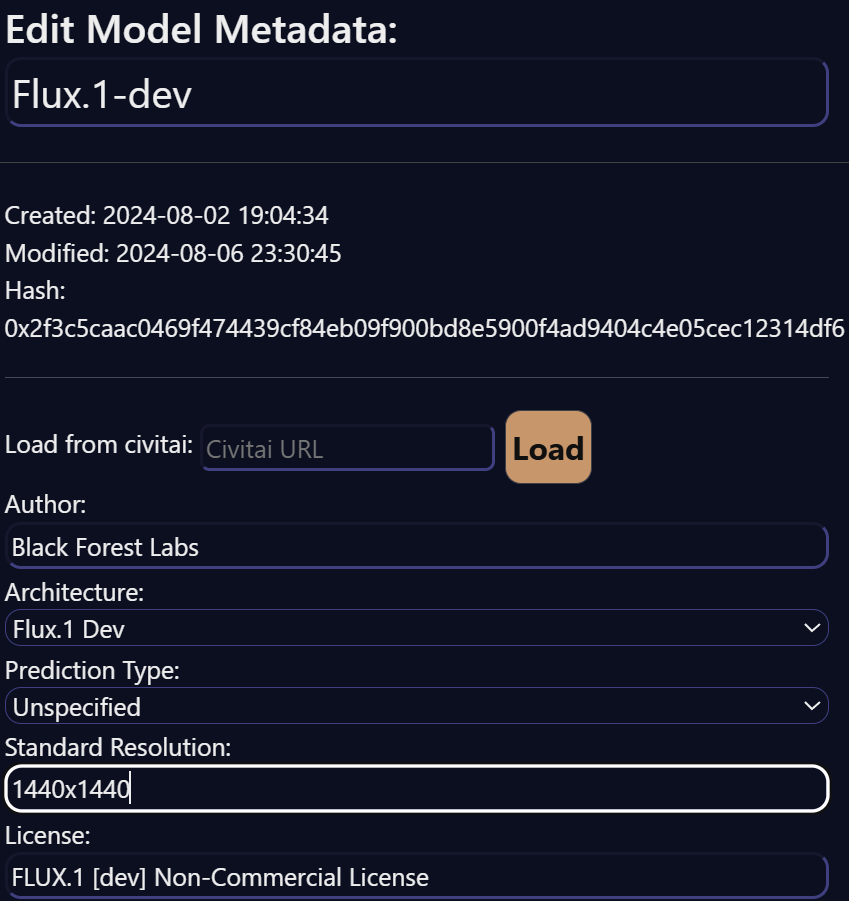
Генерируем картинки в разрешении 2К
У модели FLUX.1 [dev] «родное» разрешение — 2К. То есть «квадратом по умолчанию» является не 1024 ✕ 1024, а 1440 ✕ 1440 (со всеми производными — при использовании соотношения сторон, отличного от 1:1). SwarmUI об этом не знает, но метаданные модели легко отредактировать вручную на вкладке Models, после чего все соотношения сторон автоматически будут пересчитываться исходя из указанного разрешения.
info
Если ты отредактируешь метаданные модели вручную, то в настройках апскейла стоит указывать повышение разрешения в 1,4 или 1,5 раза, а не вдвое.
Делаем кадры из фильмов: 16:9
Flux поддерживает генерацию кадров с соотношением сторон 16:9 и разрешением 1920 ✕ 1080 непосредственно, без апскейла. При выборе этого разрешения композиция кадра может меняться в сторону некоторой киношности; возможно, в таком соотношении сторон в обучающей базе модели присутствовали скриншоты из фильмов.
Негативные ключевые слова
Одним из серьезных ограничений Flux стало отсутствие поддержки негативных ключевых слов. Это связано с рекомендацией разработчиков использовать параметр CFG в значении 1. С этим значением негативные ключевые слова не работают ни в одной модели, включая Flux.
Как работают негативные ключевые слова
При использовании параметра CFG, отличного от единицы, модель генерирует предсказания дважды — один раз на основе cond prompt (основной запрос) и один раз на основе uncond prompt (может содержать как негативные ключевые слова, так и просто шум или пустой запрос). Параметр CFG управляет тем, насколько сильно учитывать cond prompt по сравнению с uncond prompt; разница между этими двумя предсказаниями увеличивается в зависимости от величины CFG scale. Если CFG = 1, то uncond просто не генерируется, что вдвое сокращает время генерации.
Итак, разработчики FLUX.1 [dev] рекомендуют всегда использовать CFG равный единице, что, с одной стороны, является «родной» конфигурацией модели и сокращает время генерации (напомним, модель — тяжелая, генерация довольно медленная), а с другой — не позволяет использовать негативные ключевые слова.
Спустя короткое время пользователи нашли сразу несколько способов обойти это ограничение, но работать они будут только в версии [dev]; «дистиллированная» версия schnell поддержки негативных ключевых слов не получила.
Способ 1: Flux Guidance Scale
Устанавливаем CFG = 1,8, Flux Guidance Scale = 2,3, и негативные ключевые слова начинают работать. Обратная сторона медали: генерация происходит вдвое медленнее, зато в качестве дополнительного бонуса модель становится гораздо более отзывчивой к токенам, описывающим стилизацию картинки.
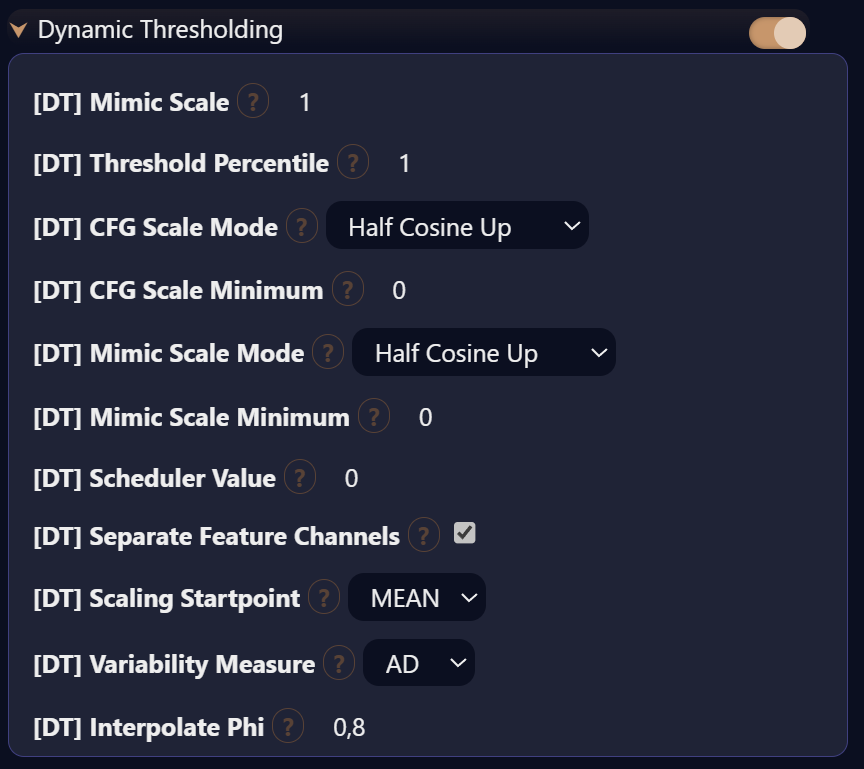
Способ 2: Dynamic Thresholding
Дальнейшее повышение параметра CFG неизбежно приводит к «выгоранию» картинки, однако бороться с «выгоранием» вследствие высоких значений CFG разработчики давно научились, используя динамическое масштабирование.

Так что можно просто увеличить параметр CFG, указав, например, значение 4, и использовать встроенный инструмент Dynamic Thresholding (DynamicCFG), для которого нужно точно подобрать параметры. Недостатки те же; дополнительно страдает реалистичность (лечится уменьшением Flux Guidance Scale из первого варианта решения), а в некоторых изображениях замечено падение качества картинки (которое компенсируется вторым проходом или апскейлом). Рекомендую начать с настроек, как на скриншоте ниже.
Пользователи comfy могут скачать готовый воркфлоу с сайта Сivitai.
Способ 3: Perp-Neg
Пользователь Reddit предлагает такое решение, использующее ноду Perp-Neg (perpendicular component of the negative prompt) в ComfyUI. К сожалению, простого способа включить эту ноду в SwarmUI я не нашел, но пользователям Comfy она доступна.
Раскрываем креативность модели
Пользователи сразу обратили внимание, что из модели убрали поддержку множества стилей и имен художников. Однако недавно в SwarmUI был добавлен параметр Flux Guidance Scale (он же Flux Distilled Guidance) из вкладки Sampling. Манипуляции им помогают добиться большей креативности модели. Этот параметр работает не так же, как CFG, который остается в значении 1.
Вероятно, разработчики модели обучили ее, как должны выглядеть изображения при тех или иных значениях CFG, что и регулируется данным параметром. Значение Flux Guidance Scale по умолчанию — 3,5. Уменьшение этого значения поможет добиться большей креативности и не приведет к блеклости создаваемых изображений, как это было бы в случае сильного понижения параметра CFG.


Значение параметра Flux Distilled Guidance трудно переоценить; оно имеет сильное влияние на стиль и «артистичность» изображения. Этот параметр может принимать значения как меньшие единицы, так и заметно большие, однако с практической точки зрения интерес представляют, вероятно, значения из диапазона 0,5–4 (значение по умолчанию – 3,5). С ростом Flux Distilled Guidance рисованная картинка постепенно упрощается, пропадают карандашные штрихи, мазки краски, исчезает текстура бумаги. Когда значение Flux Distilled Guidance добирается до дефолтных 3,5, рисунок приобретает практически полностью «цифровой» вид.

Flux Guidance можно комбинировать со значениями основного CFG, отличными от единицы, однако здесь нужно быть осторожным: если CFG больше единицы, то шкала возможных значений Flux Guidance будет еще уже, и в дефолтном значении 3,5 картинка «выгорает».
Проиллюстрирую вышесказанное двумя галереями, в которых неизменны все параметры генерации, за исключением Flux Guidance. В первой галерее значение CFG = 1, во второй CFG = 2.
Я сгенерировал два набора изображений, попытавшись добиться стилизации под акварельный рисунок. Цель — примерно такая картинка.

С параметрами по умолчанию (CFG = 1, Flux Distilled Guidance = 3,5) рисунок, как и ожидалось, имеет «цифровой» вид; установка Flux Distilled Guidance = 1 дает довольно невнятный результат, зато другие значения, включая значения меньше единицы, выдали вполне убедительную стилизацию.


Выводы
Flux на момент публикации статьи все еще обласкан вниманием сообщества. Некоторые заложенные в модель ограничения уже научились обходить; оказалось, что модель вполне поддается обучению. Уже появились первые лоры и ремиксы (пока более интересные, чем полезные, как это обычно и бывает с новыми архитектурами). Поддержка Flux в интерфейсе WebUI Forge и возможность запуска модели на старых видеокартах благодаря появлению менее требовательных к железу сжатых версий, несомненно, добавят ей популярности.