В поисках секретов
Используем силу регулярок при атаке и защите

Поиск секретов (Secrets Detection) — это процесс обнаружения и удаления так называемых чувствительных данных: паролей, ключей API, токенов доступа, настроек, которые могут случайно оказаться в исходном коде, конфигурационных файлах или других артефактах разработки. Такие лазейки дают злоумышленнику легкий доступ к важным системам и сервисам, что приведет к утечке данных или полной компрометации.
Кстати, многие отрасли требуют соблюдения строгих стандартов безопасности: GDPR, HIPAA, PCI DSS и других. Поиск и защита секретов — одна из составляющих соответствия этим стандартам.
Какие методы автоматизации выбрать?
Искать секреты вручную — все равно что просеивать песок в поисках крупицы золота. Поэтому автоматизация — единственное надежное решение. Искать секреты на потоке можно, например, с помощью регулярных выражений или путем анализа энтропии. У каждого из подходов — свои плюсы и минусы.
Регулярные выражения
Регулярные выражения (regular expressions, regex, регулярки) — это мощный инструмент для манипуляций с текстом, использующий специальный синтаксис шаблонов, чтобы искать, менять и вытаскивать данные.
Среди плюсов:
- Точность и возможность тонкого контроля. Мы можем задавать любые специфические паттерны для обнаружения строк, что минимизирует количество ложных срабатываний. Это особенно полезно для поиска конкретных типов секретов, таких как ключи API, пароли и токены доступа.
- Гибкость. Поскольку регулярные выражения поддерживают сложные шаблоны, мы можем искать самую разную инфу, включая email-адреса, IP-адреса, номера кредитных карт и любую другую чувствительную информацию.
- Простота внедрения. Многие среды разработки и редакторы кода имеют встроенную поддержку regex, также есть библиотеки почти для любых языков программирования. Это позволяет легко интегрировать регулярки в любой проект.
- Автоматизация. С использованием систем CI/CD regex можно настроить для автоматического сканирования кода при каждом коммите, что помогает быстро обнаруживать и устранять уязвимости. Некоторые инструменты, например Gitleaks, позволяют использовать pre-commit hook, что повышает уровень защиты от утечек.
Так в чем подвох? Если все так прекрасно, то зачем вообще использовать что‑то еще? Дело в том, что у этого метода также есть и минусы.
- Зависимость от шаблонов. Регулярки эффективны только для поиска известных шаблонов и могут пропускать секреты, которые им не соответствуют. Если формат меняется или используется уникальный, то инструмент на базе регулярных выражений может ничего не обнаружить.
- Сложность создания регулярных выражений и управления ими. Написание эффективных и безопасных регулярок может быть непростой задачей, особенно для нестандартных шаблонов.
- Ложные срабатывания. Если шаблон слишком общий, он обнаруживает строки, которые не являются секретами. Поэтому фильтровать и анализировать придется дополнительно и уже ручками.
- Производительность. Сложные регулярные выражения могут медленно работать на больших файлах или множестве файлов.
Анализ энтропии
Помимо регулярных выражений, при поиске секретов применяют еще один эффективный метод — анализ энтропии. Для начала давай разберем основные термины.
Энтропия — это показатель, который позволяет оценить степень случайности или, наоборот, предсказуемости данных. В контексте поиска секретов в коде он помогает выделить фрагменты, которые отличаются от остального текста по своей структуре и, возможно, содержат скрытую информацию, такую как пароли, ключи или токены. Чем выше энтропия, тем более случайная и непредсказуемая строка.
Для расчета энтропии строки есть математическая формула Клода Шеннона. Общий процесс вычисления энтропии выглядит так:
- Чтение строки: сначала берется строка из кода или файла, например
a9$L2@xZ. - Подсчет символов: подсчитывается количество каждого символа в строке.
- Вычисление вероятности: определяется, как часто каждый символ появляется в строке. Например,
aвстречается один раз из восьми символов. - Расчет энтропии.
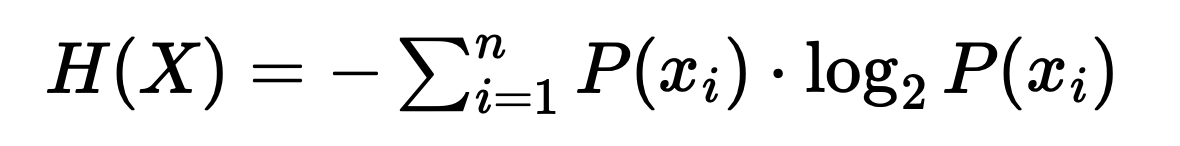
где
- H(X) — энтропия строки X;
- P(xi) — вероятность появления символа xi;
- n — количество уникальных символов в строке.
Секреты, такие как пароли или ключи API, часто имеют высокую энтропию, потому что они созданы для безопасности и содержат много случайных символов. Анализ энтропии помогает обнаруживать такие строки в коде, поскольку обычный текст (например, комментарии или обычные переменные) чаще всего имеет низкую энтропию.
После вычисления энтропии устанавливается некий порог, выше которого все строки считаются потенциальными секретами. Он зависит от конкретной среды и типов данных, но часто выбирается эмпирически. Дальше надо фильтровать и анализировать найденные строки.
А теперь о преимуществах и недостатках этого метода. Преимущества:
- Обнаружение неизвестных шаблонов. Использование энтропии позволяет выявлять случайные строки, которые могут не соответствовать известным шаблонам секретов.
- Автоматическое обновление. Метод не требует постоянного обновления правил или шаблонов при изменении формата секретов.
- Широкий охват. Можно выявлять разные типы секретов без создания специфических шаблонов.
Анализ энтропии удобный, но не идеальный метод. Вот какие у него есть минусы:
- Ложные срабатывания. Увы, пока что не существует ни одного метода без этого косяка. Высокая энтропия может быть у строк, которые не являются секретами (например, хеши, случайные данные), что приводит к ложным срабатываниям.
- Сложность настройки. Способ требует тщательной настройки порогов энтропии, чтобы сбалансировать точность и количество ложных срабатываний.
- Производительность. Анализ энтропии может быть вычислительно затратным, особенно для больших объемов данных.
Как видишь, сложность настройки и затрата ресурсов — неизбежные минусы в любом случае. Но детали могут отличаться в зависимости от реализации того и другого метода.
Какие есть инструменты?
Поиск секретов — один из процессов разработки безопасного программного обеспечения. По ГОСТ 56939 здесь мы также можем использовать инструменты статического анализа. Однако практика показывает, что его качество оставляет желать лучшего. Поэтому в рамках исследования рассмотрим три инструмента:
- Gitleaks;
- TruffleHog;
- Detect Secrets.
Gitleaks — это инструмент для обнаружения секретов преимущественно в репозиториях Git, но при нормальной настройке он также может сканировать локальные исходные данные. Этот инструмент использует как регулярные выражения, так и анализ энтропии для поиска конфиденциальной инфы, что делает его невероятно полезным для предотвращения утечек информации.
Gitleaks поддерживает множество шаблонов для разных секретов, имеет возможность гибкой настройки — пользователь сам может редактировать правила и шаблоны для более точного обнаружения. Gitleaks легко интегрируется с пайплайнами CI/CD, обеспечивая автоматическое сканирование на этапе разработки. А еще он бесплатный и у него активное сообщество, что способствует его развитию и улучшению. Но здесь есть недостаток: анализ энтропии не всегда может быть точным и требует тщательной настройки порогов.
TruffleHog находит секреты в репозиториях Git и других системах контроля версий. Он применяет регулярные выражения для обнаружения известных типов секретов, а до версии 3 включал и анализ энтропии. Несмотря на некоторые ограничения, такие как производительность и ложные срабатывания, TruffleHog остается популярным выбором благодаря простоте использования.
Последний в нашем обзоре — Detect Secrets. Чтобы обнаружить секретную информацию, он использует комбинацию регулярных выражений, анализа энтропии и спецплагинов. Благодаря своей гибкости и возможности интеграции с CI/CD Detect Secrets пользуется популярностью среди разработчиков и специалистов по безопасности. Но имей в виду: чтобы все работало эффективно, придется попотеть на этапе настройки и фильтрации ложных срабатываний.
Краткая характеристика базовых инструментов

Оцениваем эффективность инструментов на практике
У каждого из этих инструментов свои тест‑кейсы, но мы нашли кое‑что поинтереснее. Тестировать будем на OWASP WrongSecrets. Этот проект предоставляет интерактивную платформу, где разработчики и специалисты по безопасности могут учиться на практике, как правильно хранить секреты, такие как API-ключи, пароли, токены доступа и конфиденциальные данные, и управлять ими. Он специально создан для демонстрации неправильного обращения с секретами в приложениях и для обучения лучшим практикам их защиты. Это делает его идеальной тестовой средой инструментов, предназначенных для поиска и управления секретами.
Посмотрим, что найдут инструменты, если мы не будем трогать настройки по умолчанию.
Gitleaks
Для запуска инструмента использовалась следующая команда:
docker run -v /путь/до/wrongsecrets-master/:/path zricethezav/gitleaks:latest detect --no-git --source="/path" -r="/path/gitleaks_report.json"Здесь папка с исходниками локальная, поэтому используется ключ --no-git. В результате сканирования мы получили файл gitleaks_report., содержащий 20 найденных секретов. Из них 9 секретов признаны ложно положительными.
Для чистоты эксперимента запустим стандартное сканирование, но с конфигурационным файлом, который предлагают разработчики Gitleaks:
docker run -v /исходная/директория:/path zricethezav/gitleaks:latest detect --no-git --config="/path/gitleaks.toml" --source="/path/wrongsecrets-master -r="/path/gitleaks_report.json""И снова получим 20 найденных секретов, из которых 9 — ложные срабатывания.
TruffleHog
Этот инструмент запускался следующей командой:
run --rm -it -v "$PWD:/pwd" trufflesecurity/trufflehog:latest filesystem /pwd/wrongsecrets-master/ > trufflehog_local_report.txt
Полученный файл trufflehog_local_report. не содержал ни одного найденного секрета! В связи с этим пришлось выполнить ряд манипуляций:
- Создать конфигурационный файл
trufflehog_config.для более обширного и точного анализа.toml - Добавить ключи:
--debug(включает режим отладки для получения более подробной информации о процессе сканирования),--trace(включает более подробный уровень отладки, который может помочь понять, что именно сканируется и какие действия выполняются),--json(включает вывод результатов в формате JSON, что удобно для последующего анализа). - Изучить результаты.
Полная команда для запуска в этом случае выглядела так:
docker run --rm -it -v "$PWD:/pwd" -v "$PWD/trufflehog_config.toml:/config/trufflehog_config.toml" trufflesecurity/trufflehog:latest filesystem /pwd/wrongsecrets-master/ --debug --trace --jsonПри этом удалось найти лишь один секрет. Оказалось, что TruffleHog не может правильно обрабатывать некоторые данные и в итоге пропускает важные секреты. Так что он подойдет для репозиториев и текстовых файлов, но данные других типов сканировать им почти бесполезно.
В общем, TruffleHog имеет слишком много ограничений, а значит, выбывает из нашей гонки.
Detect Secrets
Запускается инструмент следующей командой:
detect-secrets scan --all-files ./wrongsecrets-master/ > detect_sec.txt
Полученный файл detect_sec. содержал 66 секретов. Из них подтверждены 42.
Таким образом, при применении стандартных настроек представленных инструментов лучше всего себя показали Detect Secrets и Gitleaks.
Теперь запустим инструменты на том же тестовом примере, но полностью отключим анализ энтропии.
Начнем с Detect Secrets. Его используют для анализа плагинов и фильтров. Фильтры применяются для уменьшения ложных срабатываний и отсеивают потенциальные секреты по определенным критериям, прежде чем результаты будут проверены плагинами. Плагины — это и есть основные настройки, каждая из которых специализируется на поиске определенного типа секретов в файлах. Есть возможность написать собственный фильтр и подключить его к сканированию. Для просмотра списка плагинов есть команда:
detect-secrets scan --list-all-pluginsВ результате мы получим все используемые в сканировании плагины. Те, что отвечают за анализ энтропии, носят названия Base64HighEntropyString и HexHighEntropyString. Их нам и надо отключить для анализа. Запустим сканирование:
detect-secrets scan --all-files --disable-plugin Base64HighEntropyString --disable-plugin HexHighEntropyString ./wrongsecrets-master > ./detect_sec_no_entropy.txt
Получаем файл, содержащий 42 секрета. Из которых только 23 — истинные. Таким образом, мы выловили куда меньше утечек, чем в предыдущем сканировании.
Теперь напишем regex-правила в формате TOML для Gitleaks. Пусть у нас будет такой базовый набор:
title = "Enhanced Gitleaks Configuration"version = 2[[rules]]id = "AWS Access Key"description = "AWS Access Key"regex = '''AKIA[0-9A-Z]{16}'''tags = ["key", "AWS"][[rules]]id = "AWS Secret Key"description = "AWS Secret Key"regex = '''(?i)aws(.{0,20})?['"][0-9a-zA-Z\/+]{40}['"]'''tags = ["key", "AWS"][[rules]]id = "Google API Key"description = "Google API Key"regex = '''AIza[0-9A-Za-z-_]{35}'''tags = ["key", "Google"][[rules]]id = "Slack Token"description = "Slack Token"regex = '''xox[baprs]-([0-9a-zA-Z]{10,48})'''tags = ["token", "Slack"][[rules]]id = "SSH Private Key"description = "SSH Private Key"regex = '''-----BEGIN (RSA|DSA|EC|OPENSSH|PGP) PRIVATE KEY-----'''tags = ["key", "SSH"][[rules]]id = "Generic API Key"description = "Generic API Key"regex = '''(?i)(apikey|api_key|secret_key|client_secret|access_token)[\s]*[=:][\s]*['"]?[A-Za-z0-9\/+=-_]{32,64}['"]?'''tags = ["key", "API"][[rules]]id = "Generic Secret"description = "Generic Secret"regex = '''(?i)(secret|password|pwd|token|key|auth)[\s]*[=:][\s]*['"]?[A-Za-z0-9\/+=-_]{8,128}['"]?'''tags = ["secret"][[rules]]id = "Database Connection String"description = "Database Connection String"regex = '''(?i)(mongodb|postgres|mysql|sqlserver|redis|couchdb|oracle):\/\/[^\s]+'''tags = ["database", "connection"][[rules]]id = "Google OAuth Client ID"description = "Google OAuth Client ID"regex = '''[0-9]+-[0-9A-Za-z_]{32}\.apps\.googleusercontent\.com'''tags = ["oauth", "Google"][[rules]]id = "Google OAuth Client Secret"description = "Google OAuth Client Secret"regex = '''(?i)("client_secret":\s*["'][A-Za-z0-9-_]{24}["'])'''tags = ["oauth", "Google"][[rules]]id = "Private Key"description = "Private Key"regex = '''-----BEGIN PRIVATE KEY-----'''tags = ["key", "private"][[rules]]id = "Heroku API Key"description = "Heroku API Key"regex = '''(?i)heroku[\s]*[=:][\s]*['"]?[0-9a-fA-F]{32}['"]?'''tags = ["key", "Heroku"][[rules]]id = "JSON Web Token"description = "JSON Web Token"regex = '''eyJ[A-Za-z0-9-_=]+\.eyJ[A-Za-z0-9-_=]+\.?[A-Za-z0-9-_.+/=]*'''tags = ["token", "JWT"]При сканировании с использованием такого набора правил мы получили 78 секретов, из которых 46 оказались истинными. Почему этот результат лучше предыдущего? Да потому, что правила были написаны вручную и охватили большее количество утечек, что, однако, не избавило нас от ложных срабатываний.
Вот что получится, если дополнить эти правила анализом энтропии.
title = "Enhanced Gitleaks Configuration with Extended Entropy Analysis"version = 2[[rules]]id = "AWS Access Key"description = "AWS Access Key"regex = '''AKIA[0-9A-Z]{16}'''tags = ["key", "AWS"]entropy = 3.5[[rules]]id = "AWS Secret Key"description = "AWS Secret Key"regex = '''(?i)aws(.{0,20})?['"][0-9a-zA-Z\/+]{40}['"]'''tags = ["key", "AWS"]entropy = 3.5[[rules]]id = "Google API Key"description = "Google API Key"regex = '''AIza[0-9A-Za-z-_]{35}'''tags = ["key", "Google"]entropy = 3.5[[rules]]id = "Slack Token"description = "Slack Token"regex = '''xox[baprs]-([0-9a-zA-Z]{10,48})'''tags = ["token", "Slack"]entropy = 3.5[[rules]]id = "SSH Private Key"description = "SSH Private Key"regex = '''-----BEGIN (RSA|DSA|EC|OPENSSH|PGP) PRIVATE KEY-----'''tags = ["key", "SSH"]entropy = 3.5[[rules]]id = "Generic API Key"description = "Generic API Key"regex = '''(?i)(apikey|api_key|secret_key|client_secret|access_token)[\s]*[=:][\s]*['"]?[A-Za-z0-9\/+=-_]{32,64}['"]?'''tags = ["key", "API"]entropy = 3.5[[rules]]id = "Generic Secret"description = "Generic Secret"regex = '''(?i)(secret|password|pwd|token|key|auth)[\s]*[=:][\s]*['"]?[A-Za-z0-9\/+=-_]{8,128}['"]?'''tags = ["secret"]entropy = 3.5[[rules]]id = "Database Connection String"description = "Database Connection String"regex = '''(?i)(mongodb|postgres|mysql|sqlserver|redis|couchdb|oracle):\/\/[^\s]+'''tags = ["database", "connection"]entropy = 3.5[[rules]]id = "Google OAuth Client ID"description = "Google OAuth Client ID"regex = '''[0-9]+-[0-9A-Za-z_]{32}\.apps\.googleusercontent\.com'''tags = ["oauth", "Google"]entropy = 3.5[[rules]]id = "Google OAuth Client Secret"description = "Google OAuth Client Secret"regex = '''(?i)("client_secret":\s*["'][A-Za-z0-9-_]{24}["'])'''tags = ["oauth", "Google"]entropy = 3.5[[rules]]id = "Private Key"description = "Private Key"regex = '''-----BEGIN PRIVATE KEY-----'''tags = ["key", "private"]entropy = 3.5[[rules]]id = "Heroku API Key"description = "Heroku API Key"regex = '''(?i)heroku[\s]*[=:][\s]*['"]?[0-9a-fA-F]{32}['"]?'''tags = ["key", "Heroku"]entropy = 3.5[[rules]]id = "JSON Web Token"description = "JSON Web Token"regex = '''eyJ[A-Za-z0-9-_=]+\.eyJ[A-Za-z0-9-_=]+\.?[A-Za-z0-9-_.+/=]*'''tags = ["token", "JWT"]entropy = 3.5[[rules]]id = "Twilio API Key"description = "Twilio API Key"regex = '''(?i)twilio[\s]*[=:][\s]*['"]?[A-Za-z0-9-_]{32}['"]?'''tags = ["key", "Twilio"]entropy = 3.5[[rules]]id = "Stripe API Key"description = "Stripe API Key"regex = '''(?i)sk_live_[0-9a-zA-Z]{24}'''tags = ["key", "Stripe"]entropy = 3.5[[rules]]id = "SendGrid API Key"description = "SendGrid API Key"regex = '''(?i)SG\.[0-9a-zA-Z\-_]{22}\.[0-9a-zA-Z\-_]{43}'''tags = ["key", "SendGrid"]entropy = 3.5[[rules]]id = "MailChimp API Key"description = "MailChimp API Key"regex = '''(?i)[0-9a-f]{32}-us[0-9]{1,2}'''tags = ["key", "MailChimp"]entropy = 3.5[[rules]]id = "GitHub Personal Access Token"description = "GitHub Personal Access Token"regex = '''ghp_[0-9a-zA-Z]{36}'''tags = ["key", "GitHub"]entropy = 3.5[[rules]]id = "GitLab Personal Access Token"description = "GitLab Personal Access Token"regex = '''glpat-[0-9a-zA-Z\-_]{20}'''tags = ["key", "GitLab"]entropy = 3.5[[rules]]id = "Azure Storage Account Key"description = "Azure Storage Account Key"regex = '''(?i)(AccountKey|AccountKeyPrimary|AccountKeySecondary|SharedAccessSignature)=([A-Za-z0-9+\/=]{88})'''tags = ["key", "Azure"]entropy = 3.5[[rules]]id = "Salesforce Security Token"description = "Salesforce Security Token"regex = '''[A-Za-z0-9]{24}'''tags = ["token", "Salesforce"]entropy = 3.5Мы получили 3810 утечек! Откуда такой результат? Проект содержит имена переменных, политик и прочие данные, которые обладают высокой энтропией. Например, у названия политики AWSLoadBalancerController энтропия 3,7406015, а у AmazonEKSWorkerNodePolic — 4,0849624. На все эти и другие имена в исходных текстах и реагирует Gitleaks.
Конечно, в правилах можно прописать исключения. Они должны быть описаны в полях [ (для исключения каталогов или файлов) и [ (для исключения ключевых слов), что в разы сократит количество ложных срабатываний.
Также в правилах можно менять уровень энтропии, на которую реагирует Gitleaks. Например, если мы выставим уровень 4.0, то получим уже 2912 утечек, а при 4.5 количество срабатываний упадет до 126. С учетом всего вышеописанного мы имеем максимально гибко настраиваемый инструмент, который работает как с анализом энтропии, так и с регулярными выражениями.
Подводим итоги
Итак, мы рассмотрели два метода поиска утечек и три инструмента. Результат их сравнения — в таблице ниже.
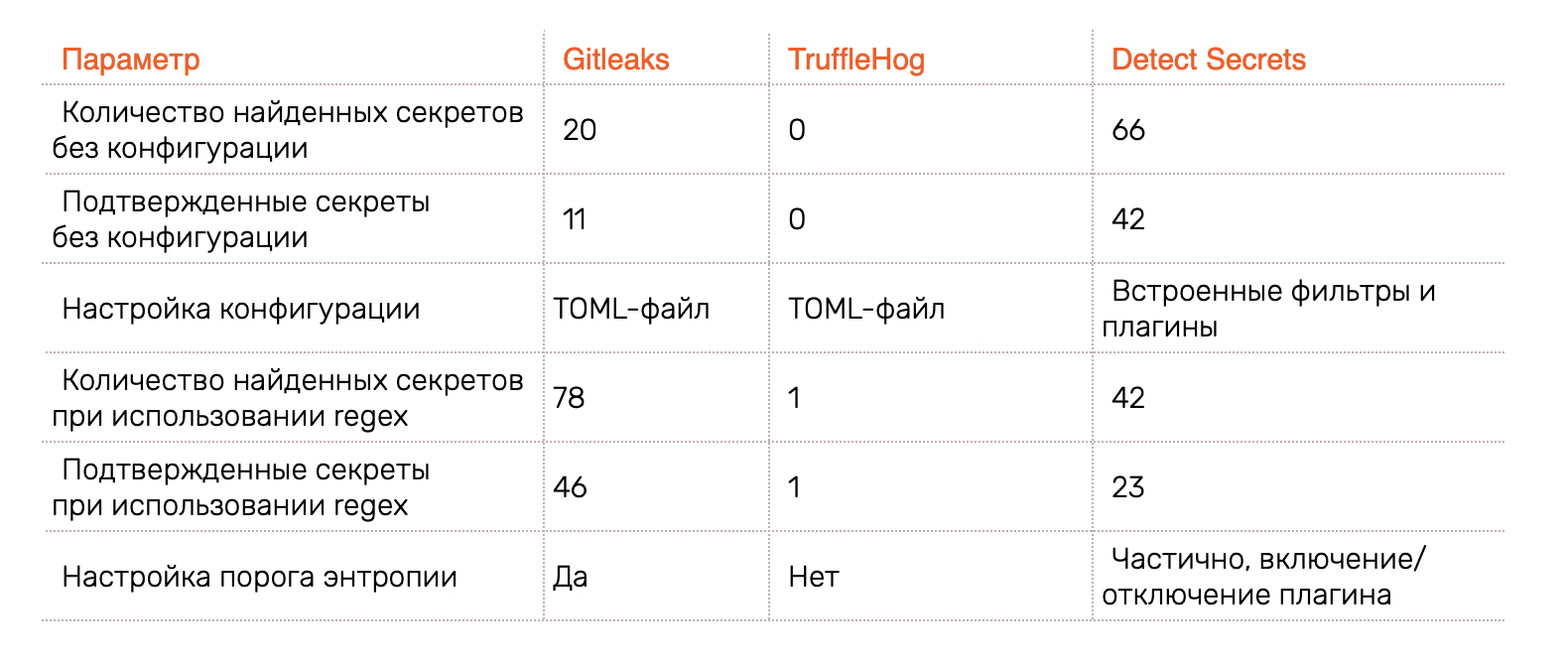
Сказать однозначно, что анализ энтропии лучше, чем regex, или наоборот, невозможно. Каждый метод дает ложные срабатывания или не находит те или иные утечки. Так что лучшей практикой будет использовать оба метода с тонкой настройкой под собственные требования.
Регулярные выражения и анализ энтропии прекрасно дополняют друг друга: первый метод точно бьет по конкретным целям, второй вычисляет скрытые паттерны. Вместе они создают мощный дуэт, который поможет тебе обнаружить даже самые замаскированные секреты.
Лучшим инструментом по результатам нашего небольшого анализа стал Gitleaks, в настройках которого ты можешь как писать собственные правила, так и выставлять нужный уровень энтропии. Но если нет возможности и желания нырять в пучину написания кастомных правил, можно ограничиться Detect Secrets, который показал себя достаточно хорошо при полном отсутствии дополнительных настроек.
В следующей статье мы планируем подробнее рассказать про Gitleaks: разберем способы написания правил, тонкости настройки, а также внедрение этого инструмента в CI/CD.