Руби наотмашь
Исследуем архитектуру приложения на Ruby и учимся его реверсить

Когда‑то о Ruby было написано множество рекламных статей. Для тех, кто хочет более детально ознакомиться с его концепцией и внутренней структурой, есть книга Ruby under a microscope. В общем, как ты уже понял, цель сегодняшней статьи — не постижение дзена программирования на Ruby, а сухой практический разбор особенностей реверса приложений, реализованных на этой экзотике.
Задача
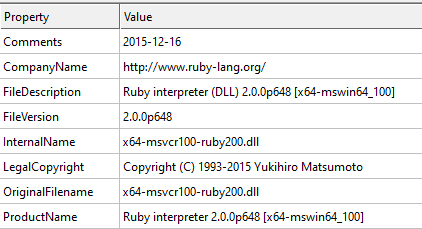
Итак, дано приложение, читающее и валидирующее некий бинарный файл. Нам нужно разобраться с алгоритмом валидации. Первичный автоматический анализ приложения при помощи Detect It Easy на этот раз нам толком ничего не дает — приложение детектится как собранное из C++ в банальном Microsoft Visual Studio 2015. Однако в комплект динамических библиотек программы входит интересный файл x64-msvcr100-ruby200., на который полно ссылок из исполняемого модуля. Файл позиционирует себя как интерпретатор Ruby за авторством самого отца‑основателя Юкихиро Мацумото со ссылкой на соответствующий сайт.
Вдобавок в комплект программы входит около двух с половиной тысяч файлов *., при ближайшем рассмотрении оказавшихся обычными текстовыми ничем не защищенными Ruby-скриптами. Как ты уже догадался, есть маленький подвох, без которого эту статью писать было бы неинтересно: ни в одном из этих файлов обращений к нашему целевому файлу не нашлось, а значит, придется загружать нашу программу в отладчик x64dbg и искать обращение к файлу в динамике интерпретированного кода.
Исследуем программу
Действуем по стандартной схеме, наверняка уже знакомой тебе по моим предыдущим статьям. Ставим точку останова на функцию чтения файла kernel32.. Конечно же, при загрузке программы будут тысячи подобных обращений ко всевозможным файлам настроек и библиотек, входящих в пакет, но нам немного облегчит задачу мониторинг чтения файлов с помощью тоже известной нам программы Process Monitor (ProcMon). Благодаря ей мы замечаем, что чтение нашего искомого файла, в отличие от всех остальных, идет исключительно блоками по 0x10000 байт. Поэтому, чтобы отсечь все ненужные нам чтения, можно поставить в качестве условия для останова Size==0x10000.
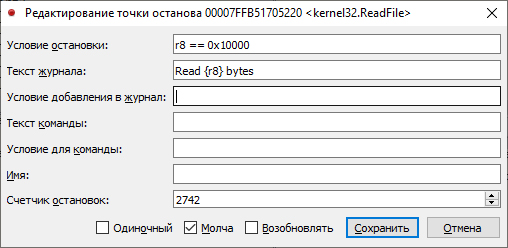
Запускаем нашу программу и ждем достижения этой точки. Проанализируем стек вызова полученного ReadFile.

Верхние пять вызовов представляют собой нативную обвязку чтения файла и нам неинтересны. А вот ниже явно идут два вложенных вызова интерпретатора, до боли знакомых нам по разбору виртуальных машин других скриптовых языков. Чтобы не отвлекаться на повторение того, что я многократно писал в своих предыдущих статьях, постараюсь сказать в двух словах. Любой, даже самый упоротый (вроде питона) интерпретатор скриптового языка никогда не разбирает текстовую семантику во время выполнения. Для оптимизации работы интерпретатора во время загрузки модуля (класса, объекта, метода и так далее) происходит компиляция текста в натив или шитый байт‑код, сам процесс называется JIT-компиляцией (just-in-time, в нужное время) или попросту динамической компиляцией.
Разумеется, несмотря на заявленную экстравагантность, в точности так же поступает и Ruby. Про особенности JIT-компиляции для разных реализаций Ruby можно почитать на сайте patshaughnessy.net, а мы попробуем разобраться с нашей виртуальной машиной. Немного поизучав вложенные вызовы стека с предыдущего скриншота, находим основной цикл выборки команд шитого кода (выделены стрелками). В IDA код этой процедуры (sub_18001B6E0, экспортируемая функция — rb_vm_get_insns_address_table) выглядит так.
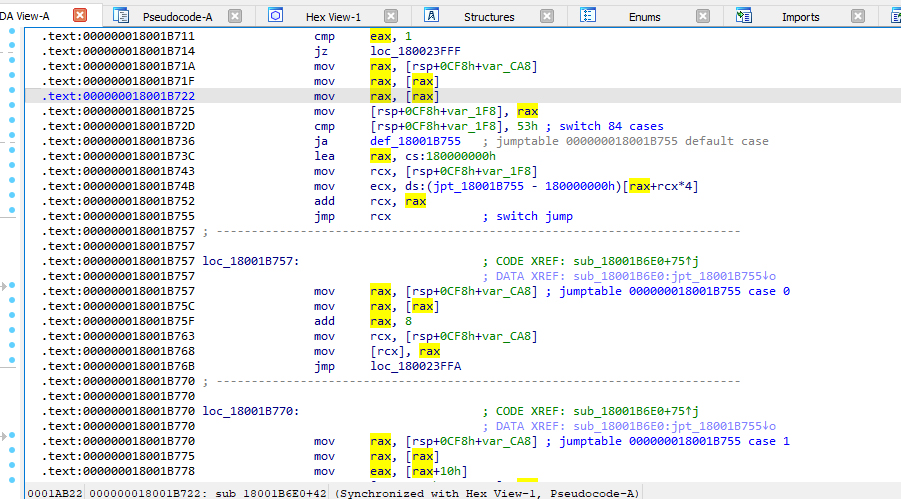
Как видим, опкод занимает 8 байт, виртуальная машина содержит 83 команды ассемблера, реализация каждой из которых представлена в этой функции. Оказывается, библиотека интерпретатора даже содержит в себе дизассемблер для компилированного байт‑кода (экспорты rb_iseq_disasm_insn, rb_iseq_disasm). Анализируя эти функции, можно найти таблицу мнемоник команд, находящуюся по адресу 180200500:
00 nop
01 getlocal
02 setlocal
03 getspecial
04 setspecial
05 getinstancevariable
06 setinstancevariable
07 getclassvariable
08 setclassvariable
09 getconstant
0A setconstant
0B getglobal
0C setglobal
0D putnil
0E putself
0F putobject
10 putspecialobject
11 putiseq
12 putstring
13 concatstrings
14 tostring
15 toregexp
16 newarray
17 duparray
18 expandarray
19 concatarray
1A splatarray
1B newhash
1C newrange
1D pop
1E dup
1F dupn
20 swap
21 reput
22 topn
23 setn
24 adjuststack
25 defined
26 checkmatch
27 trace
28 defineclass
29 send
2A opt_send_simple
2B invokesuper
2C invokeblock
2D leave
2E throw
2F jump
30 branchif
31 branchunless
32 getinlinecache
33 onceinlinecache
34 setinlinecache
35 opt_case_dispatch
36 opt_plus
37 opt_minus
38 opt_mult
39 opt_div
3A opt_mod
3B opt_eq
3C opt_neq
3D opt_lt
3E opt_le
3F opt_gt
40 opt_ge
41 opt_ltlt
42 opt_aref
43 opt_aset
44 opt_length
45 opt_size
46 opt_empty_p
47 opt_succ
48 opt_not
49 opt_regexpmatch1
4A opt_regexpmatch2
4B opt_call_c_function
4C bitblt
4D answer
4E getlocal_OP__WC__0
4F getlocal_OP__WC__1
50 setlocal_OP__WC__0
51 setlocal_OP__WC__1
52 putobject_OP_INT2FIX_O_0_C_
53 putobject_OP_INT2FIX_O_1_C_
При внимательном рассмотрении идентифицируется и сам тип интерпретатора байт‑кода, это разновидность YARV.
Генерируем ошибку
Интерпретатор мы определили, байт‑код, из которого вызывается чтение нашего файла, нашли, но что дальше? Реверсить работу с файлом, анализируя скомпилированный байт‑код, даже при наличии встроенного дизассемблера как‑то грустно. Хочется найти текстовый исходник Ruby-скрипта, хотя, конечно, не исключена возможность, что интерпретатору подсунули уже искусственно скомпилированный байт‑код. Но пока что не будем рассматривать столь крайние варианты. Попробуем хотя бы определить имя метода, вызывающего чтение файла.
Первый пришедший в голову тупой, грубый и брутальный способ добиться этого быстро и без кропотливого анализа кода — сгенерировать ошибку и надеяться, что в отчете о ней интерпретатор сам напечатает стек вызовов и возвратов. При беглом просмотре кода цикла интерпретатора мы видим, что при появлении неизвестного опкода (>) интерпретатор действительно вызывает ошибку и даже печатает стек при ее возникновении.
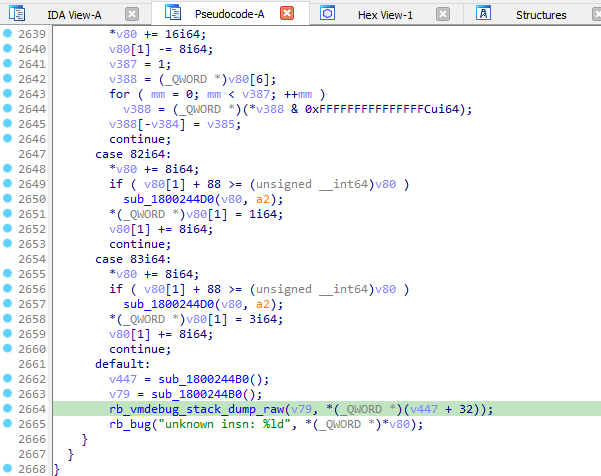
Попробуем смоделировать эту ситуацию самостоятельно. Сразу после достижения точки останова на чтении блока 0x10000 отключаем эту точку и ставим точки останова на выборку следующей команды шитого кода (на позапрошлом скриншоте это выделенный адрес 18001B722) и функции printf, через которую ведется отладочная печать стека. При достижении следующей команды мы меняем ее на невалидную (например, 84) и ждем, что именно будет печатать printf. И действительно, помимо кучи малопонятной отладочной информации о блоках и фреймах в момент возникновения ошибки, он выдает ближайший класс и метод.
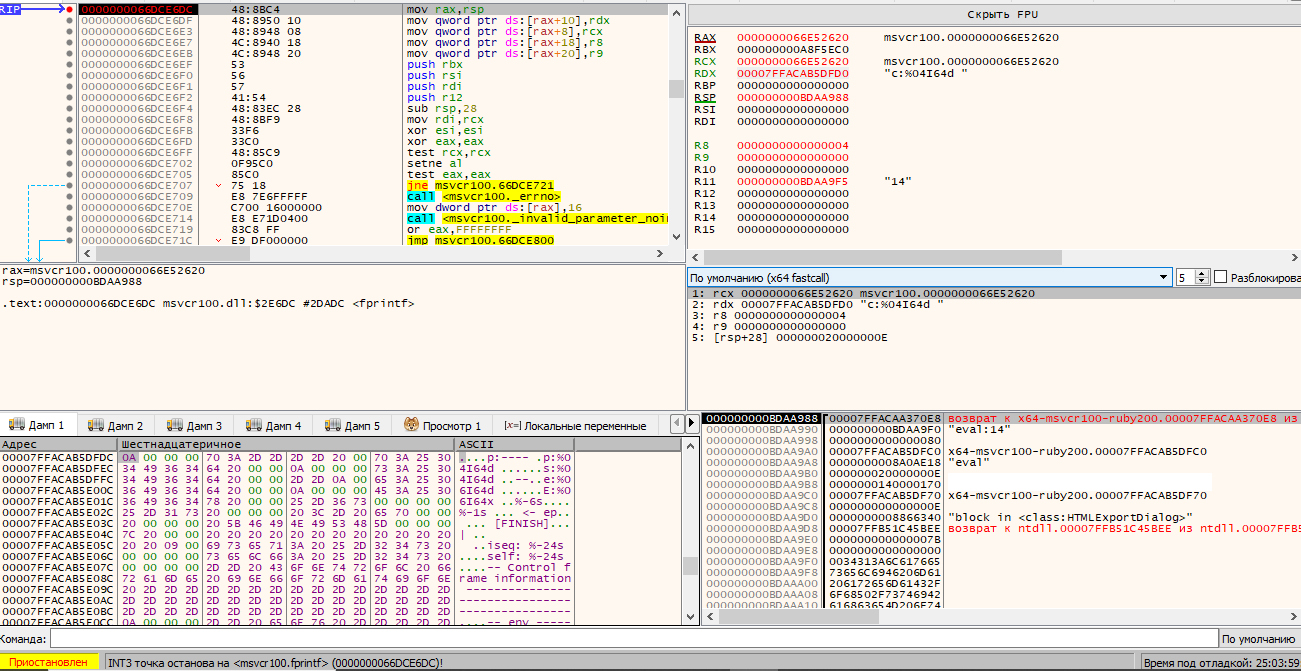
Однако это не дает нам практически ничего: судя по всему, чтение происходит при вызове eval из класса HTMLExportDialog, а по закону наибольшей подлости этот класс в открытом коде отсутствует.
Ищем альтернативу
Попробуем подойти к решению вопроса с другой стороны — еще раз проанализируем стек вызовов со скриншота в начале статьи. Исследуемый нами поток снизу упирается в вызов из ntdll и явно запущен каким‑то другим потоком. Перебирая соседние потоки, мы находим похожего кандидата — этот поток спокойно ждет в сторонке окончания вызова функции rb_eval_string_protect("PM::).
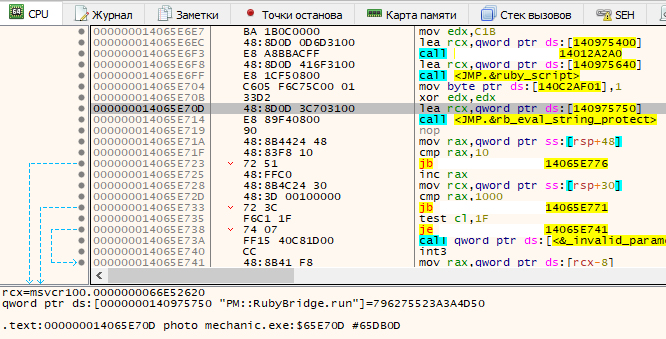
На первый взгляд, нам это тоже почти ничего не дает — как ты, вероятно, уже догадался, и PM, и RubyBridge в открытом коде тоже отсутствуют. Однако теперь у нас есть рабочая гипотеза (и за эту гипотезу частично говорит анализ кода приложения в IDA), что общение приложения с интерпретатором Ruby идет именно через вызов rb_eval_string_protect.
Поэтому убираем все предыдущие точки останова и ставим новую точку на вход этой функции. Перезапустив программу, с ходу узнаём много интересного: очень много вызовов вида PM., где ModuleName — файлы с расширением *., явно зашифрованные, среди которых есть и RubyBridge, и HTMLExportDialog, и многие другие. А главное — таким образом нашелся и код реализации PM., который эти файлы расшифровывает.
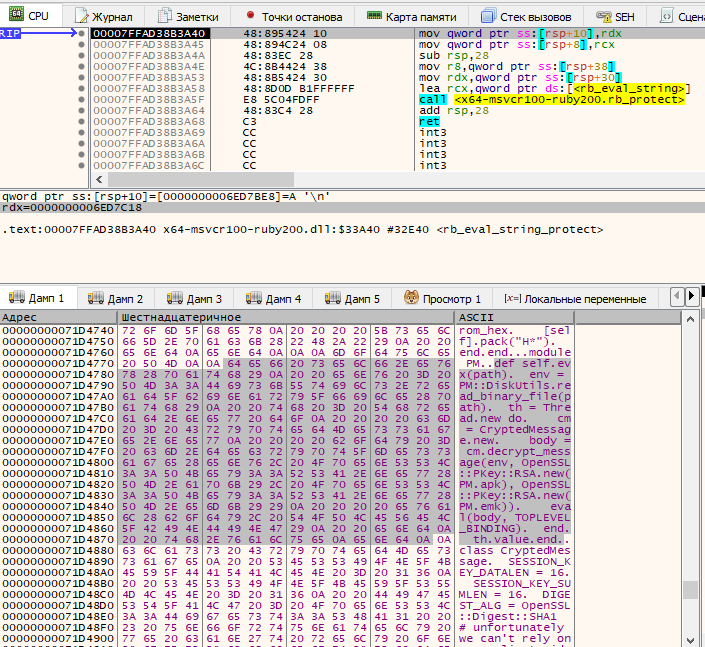
Хитрые разработчики, опасаясь злых хакеров, и сам код, и расшифровываемые им модули зашифровали несимметричным алгоритмом RSA, что ставит крест на всех попытках поправить что‑либо внутри скрипта при отсутствии секретного ключа. По счастью, такой цели перед нами не стоит, по условию задачи нам нужно всего лишь найти алгоритм валидации заданного файла, и этот алгоритм таится внутри одного из зашифрованных RSA скриптов.
Причем основная и самая сложная часть задачи уже выполнена — нам известен алгоритм шифрования защищенных скриптов, остальное — дело техники. Можно вытащить из кода открытый ключ шифрования и самому написать процедуру расшифровки модулей, можно поставить точку останова на decrypt нативной библиотеки реализации RSA и дампить уже расшифрованный код, но мы, как обычно, выбираем самый быстрый и ленивый способ.
На предыдущем скриншоте видно, что evx реализован через eval, поэтому мы ставим точку останова на функцию x64-msvcr100-ruby200. и на входе ее получаем расшифрованный код модулей прямо на блюдечке. Путем несложных манипуляций находим и конечную цель нашего квеста — валидацию файла.
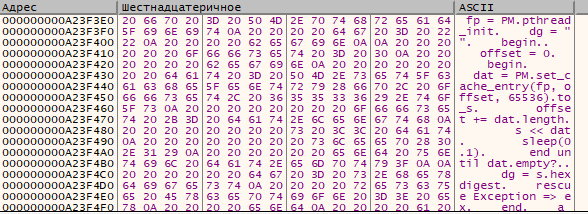
Выводы
В заключение хочу добавить, что, хотя в реальной жизни тебе навряд ли встретится так странно реализованное и извращенно защищенное приложение (как я уже говорил, обычно скриптовые языки не предназначены для создания коммерческих пакетов, а тихонько выполняют свою работу на закрытых серверах), описанный в статье опыт поможет тебе в освоении или даже проектировании собственных виртуальных машин и интерпретаторов.