Семь бед — один Semgrep
Ищем уязвимый код с помощью кастомных правил


В предыдущей статье мы показали, как находить уязвимости в приложениях с помощью динамического сканирования (DAST) на примере сканера Nuclei. Однако DAST — это лишь один из подходов к построению безопасности. В этот раз рассмотрим статический анализ и принципы, на которых он строится.
Ты, возможно, сталкивался со статическими линтерами в популярных IDE вроде VS Code. Они анализируют исходный код и дают рекомендации по улучшению. Примерно так же работает и SAST, только с уклоном в безопасность.
Благодаря SAST специалисты, ответственные за безопасность кода, backend-разработчики, инженеры Application Security, сотрудники DevSecOps и DevOps могут немного расслабиться, так как есть дополнительный уровень проверки и проблемный код не сразу попадет в продуктовое окружение.
Однако с настройками по умолчанию SAST не отличается высокой эффективностью. Чтобы выжать из него максимум, нужно добавить свои настройки — в идеале для конкретного приложения. Мы покажем, как это делать.
В качестве инструмента я выбрал Semgrep, как самый простой способ познакомиться со статическим анализом.
Напишем три правила для обнаружения уязвимостей в API:
- Broken Object Level Authorization.
- Broken Function Level Authorization.
- SQL Injection.
В качестве уязвимой кодовой базы снова возьмем специальное приложение для тестирования защищенности API — VAmPI.
Запускать нам его в этот раз не нужно, достаточно просто скачать исходный код:
git clone https://github.com/erev0s/VAmPI
cd VAmPI
Для сканирования приложения локально установим Semgrep. Он доступен на всех популярных операционных системах, а инструкция по установке есть на официальном сайте. Универсальный способ — ставить через пакетный менеджер pip:
python3 -m pip install semgrep
Чтобы запустить Semgrep со встроенными правилами, нужно перейти в директорию с исходным кодом тестируемого приложения и выполнить следующую команду:
semgrep --config=auto
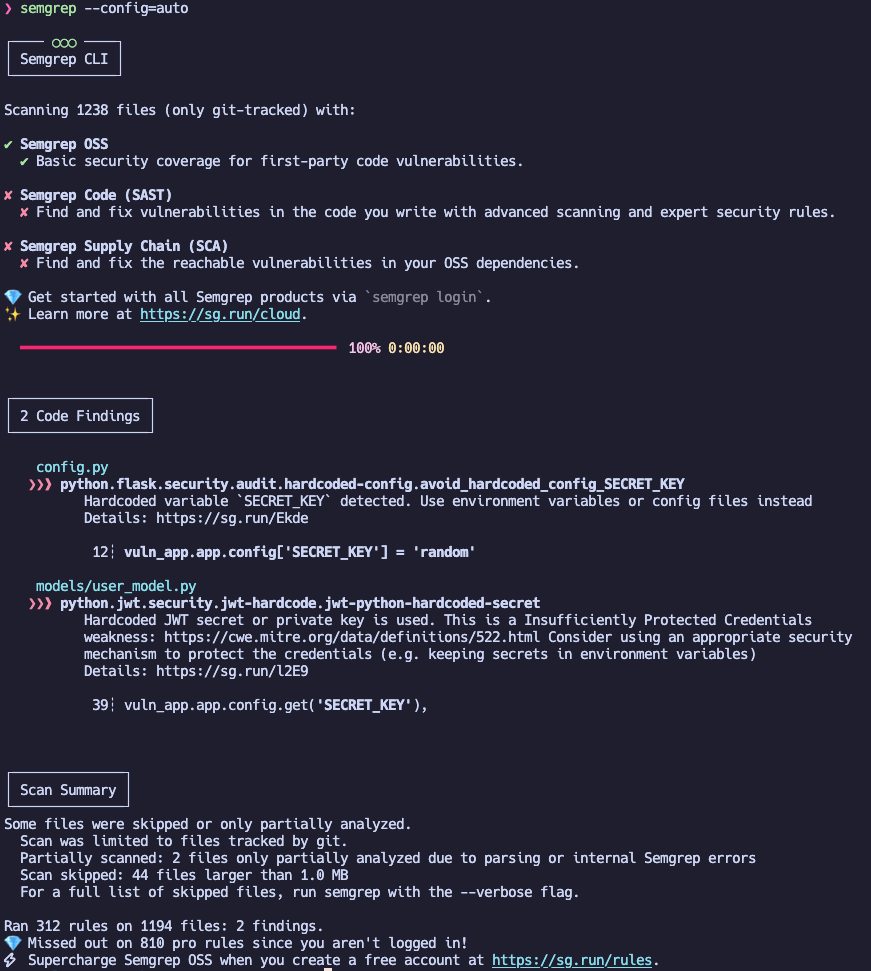
При таком запуске Semgrep обнаружил только небезопасное использование секретов в исходном коде. Это лучше, чем ничего, но в нашем уязвимом приложении точно есть и более опасные баги.
Обрати внимание, что это бесплатная версия, а разработчики явно говорят, что в платной версии заложено гораздо больше экспертизы. Возможно, в нашем примере ситуация тоже бы изменилась в лучшую сторону.
Однако мы решим проблему иначе: добавив собственные правила. Но сначала рассмотрим, как устроен SAST.
Статический анализ безопасности
Чтобы понять, как работает SAST, рассмотрим четыре подхода:
- Abstract syntax tree (AST), абстрактное синтаксическое дерево. AST помогает инструментам SAST понять структуру кода и его семантику. AST — это структура данных, представляющая синтаксическую иерархию исходного кода программы в виде дерева. Например, одним из узлов может быть вызов метода, а его аргументы будут дочерними узлами.
- Control flow graph (CFG), граф потока управления. На основе CFG инструменты SAST могут анализировать возможные пути выполнения программы. CFG представляет собой граф, где узлы обозначают базовые блоки кода (последовательности инструкций без ветвлений), а ребра — возможные пути выполнения между этими блоками. Этот граф позволяет понять, как управление передается по программе.
- Data flow graph (DFG) — граф потока данных. Анализ потока данных позволяет выявить уязвимости, связанные с неправильной передачей или использованием данных. DFG — граф, в узлах которого расположены операции, а ребра показывают поток данных между этими операциями.
- Taint analysis — анализ зараженности. Это продвинутая версия DFG, она фокусируется на отслеживании источников потенциально опасных данных (например, пользовательского ввода) через программу и проверке того, как эти данные используются. Если такие данные применяются без надлежащей фильтрации или валидации, это может привести к уязвимостям.
Как работает SAST?
Теперь по шагам посмотрим, что, собственно, делает SAST.
- Анализирует исходный код. SAST-инструменты анализируют исходный код, используя AST, CFG, DFG и другие модели, чтобы получить полное представление о структуре и логике программы.
- Ищет паттерны уязвимостей. Применяя различные правила и паттерны (например, использование небезопасных функций, неправильная обработка ошибок), инструменты SAST обнаруживают потенциальные уязвимости.
- Создает отчеты. SAST-инструменты генерируют отчеты с описанием найденных уязвимостей, указывая на проблемные места в коде.
Semgrep — это как grep?
Думаю, ты знаком с grep — это популярный инструмент для поиска текстовых строк с помощью регулярных выражений. О структуре кода, впрочем, он ничего не знает. Представь grep, который понимает код так же, как и ты. Semgrep не просто ищет совпадения по тексту, а учитывает синтаксис и структуру кода.
Пишем правило для Semgrep
Правила в Semgrep описываются на YAML.
rules: - id: no-eval pattern: eval(...) message: "Avoid using eval, as it can lead to security vulnerabilities." languages: [python, javascript] severity: warningКаждое правило обязательно содержит:
- id — уникальный идентификатор шаблона;
- pattern — шаблон, который нужно искать в коде;
- message — сообщение, которое будет выведено при совпадении;
- languages — языки программирования, на которых должно выполняться правило;
- severity — уровень важности (например, warning, error).
В примере выше Semgrep будет искать использование функции eval в коде на Python и JavaScript и выдавать предупреждение, так как использование eval может быть небезопасным.
Оператор «многоточие» — паттерн для нуля или более элементов, таких как аргументы, операторы, параметры, поля, символы.
Taint analysis
Taint analysis в Semgrep — это метод отслеживания данных, которые поступают из ненадежных источников (например, ввода пользователя) и могут быть использованы в опасных контекстах (например, в функциях, выполняющих код, таких как eval или exec). Цель taint analysis — предотвратить использование таких данных без должной обработки.
Пример простого taint-правила в Semgrep
rules: - id: taint-example pattern-sources: - pattern: request.get(...) pattern-sinks: - pattern: exec(...) message: "Potentially unsafe data is passed to exec." languages: [python] severity: error mode: taintЗдесь важно понимать основные концепции:
- источники (sources) — это места в коде, где данные считаются потенциально небезопасными. Например, данные, полученные через ввод пользователя, запросы, переменные окружения и так далее;
- санитайзеры (sanitizers) — это функции или методы, которые обрабатывают или фильтруют данные, чтобы сделать их безопасными для использования;
- приемники (sinks) — это места, где использование данных может быть опасным, например передача данных в функции, выполняющие код, или создание SQL-запросов.
В этом примере Semgrep будет искать, где данные, полученные через request., передаются в функцию exec(.... Такая схема привела бы к появлению уязвимости, которую может обнаружить и проэксплуатировать злоумышленник.
Пишем шаблоны для Semgrep
Broken Object Level Authorization
Статический анализ предполагает наличие исходного кода, поэтому мы можем учесть конкретные особенности нашего приложения. Мы знаем, что в нем есть возможности взаимодействия с книгами, и мы знаем, как это реализовано в коде. Проверим, что во всем приложении перед тем, как выполнить какую‑либо операцию с книгой, проверяется, какому пользователю она принадлежит.
В нашем учебном приложении проверка того, какому пользователю принадлежит книга, происходит прямо в теле контроллера. Поэтому и в правиле для Semgrep мы учтем ее именно так.
Создадим файл templates/ и запишем в него следующее:
rules: - id: python-bola languages: [python] message: Access to data without verifying that it belongs to the user severity: ERROR patterns: - pattern-not-inside: | $USER = User.query.filter_by(...).first() ... $OBJ.query.filter_by(...,user=$USER,...) - pattern: $OBJ.query.filter_by(...) - metavariable-regex: metavariable: $OBJ regex: BookРазберем правило:
-
pattern-not-insideговорит Semgrep, что случай, в котором переменная$USERиспользуется при обращении к переменной$OBJ, не является уязвимым; -
pattern— напротив, говорит, что обращение без$USERуязвимо; -
metavariable-regexпозволяет задать переменную$OBJкак регулярное выражение, что может быть полезно, если мы проверяем не только объектыBook.
Мы указали метод query. и прочие явные конструкции языка в правиле потому, что мы знаем, что именно так они применяются в коде нашего приложения.
Broken Function Level Authorization
Пользовательские данные — это в большинстве чувствительная информация. Проверим, что в нашем приложении нельзя получить доступ к данным пользователя без авторизации.
Опять же из понимания устройства нашей системы контроля доступа мы знаем, что в контроллерах, обрабатывающих запросы к данным пользователей, должна вызываться функция token_validator, отвечающая за авторизацию. Создадим файл templates/ и запишем в него правило:
rules: - id: python-bfla languages: [python] message: Access to user data without authorization severity: ERROR patterns: - pattern-either: - pattern-inside: | def $FUNC(...): ... $RETURN = $RESPONSE(...,$OBJ,...) ... return $RETURN ... - pattern-inside: | def $FUNC(...): ... return $RESPONSE(...,$OBJ,...) ... - pattern-not-inside: | def $FUNC(...): ... token_validator(...) ... - metavariable-regex: metavariable: $OBJ regex: .*User\\.Разберем правило:
-
pattern-either— этот оператор выполняет логическую операцию ИЛИ над одним или несколькими дочерними паттернами; - вложенные в
pattern-eitherдваpattern-insideговорят Semgrep, что мы ищем контроллер, возвращающий в ответе данные объекта$OBJ. Мы описываем сразу несколько возможных паттернов, поэтомуpattern-insideнесколько; -
pattern-not-insideучитывает, что в уязвимом контроллере нет вызова функцииtoken_validator; -
metavariable-regexпозволяет задать переменную$OBJкак регулярное выражение, что может быть полезно, если мы проверяем не только объектыUser.
Мы используем переменные $FUNC и $RESPONSE, чтобы найти контроллеры и функции подготовки ответов. Мы никак не ограничиваем их названия, поэтому Semgrep найдет все. Если бы мы хотели найти только контроллеры, названия которых начинаются с get, мы бы уточнили переменную $FUNC в metavariable-regex.
SQL Injection
Одна из самых старых, тем не менее до сих пор актуальных и опасных уязвимостей — это SQL-инъекция. Подготовим правило, проверяющее, что в нашем приложении нет небезопасных запросов к базе данных — таких, в которые попадает пользовательский ввод. Эту задачу можно решить с помощью taint analysis. Создадим файл templates/ и запишем следующее:
rules: - id: tainted-python-sqli languages: [python] severity: ERROR message: User-controlled data from a request is passed to db.execute mode: taint pattern-sinks: - patterns: - pattern: $QUERY - pattern-inside: $DB.execute(...,$QUERY,...) pattern-sources: - patterns: - pattern: $ARG - pattern-inside: | def $HANDLER(...,$ARG,...): ...Разберем правило:
-
mode:— говорит, что будет применен taint analysis;taint -
pattern-sinks— задает паттерны небезопасных мест, куда могут приходить данные; -
pattern-sources— задает, какие паттерны источников данных мы считаем небезопасными.
В нашем случае мы ищем пути, в которых данные из контроллера могут попасть в вызов метода execute.
Сканируем стенд
Чтобы запустить сканирование Semgrep с нашими шаблонами, достаточно просто перейти в директорию с исходным кодом тестируемого приложения и выполнить команду
semgrep --config templates
Здесь templates — директория, в которой находятся наши шаблоны.
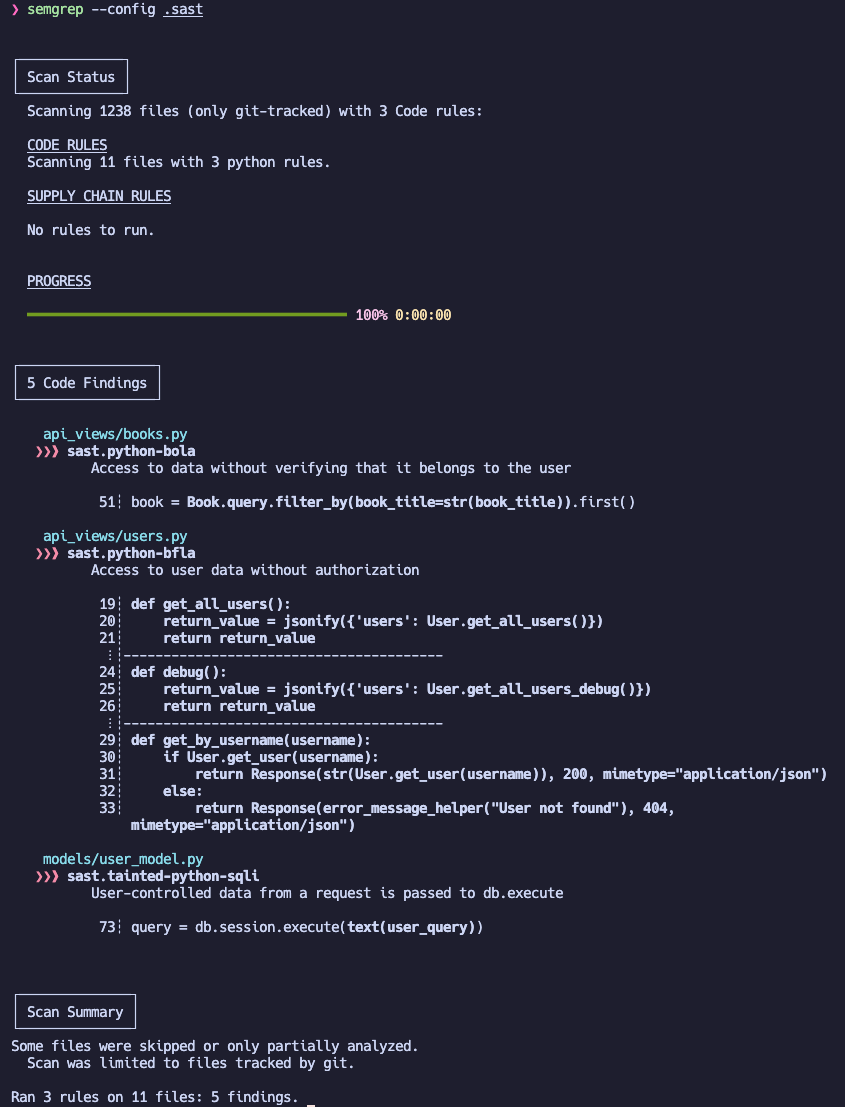
В результате запуска наших кастомных правил мы обнаружили пять уязвимостей в приложении.
Если нажать названия файлов из вывода Semgrep, то мы окажемся в месте с уязвимым кодом и сможем подтвердить уязвимость.

Выводы
Итак, в этой статье мы:
- рассмотрели особенности статического анализа безопасности приложений, базовые принципы, на которых он строится, и более продвинутый taint analysis;
- научились писать простые правила для Semgrep;
- составили три шаблона для нахождения реальных опасных уязвимостей с учетом особенностей выбранного приложения.
Важный плюс в том, что мы можем продолжать использовать один раз написанные шаблоны для новых версий текущего приложения, а также взять их за основу и для других приложений с похожей кодовой базой.